Abstract
Mental health disorders affect over 1 billion people worldwide, yet access to care remains limited by workforce shortages and cost constraints. While AI systems show therapeutic promise, current alignment approaches optimize objectives independently, failing to balance patient preferences with clinical safety.
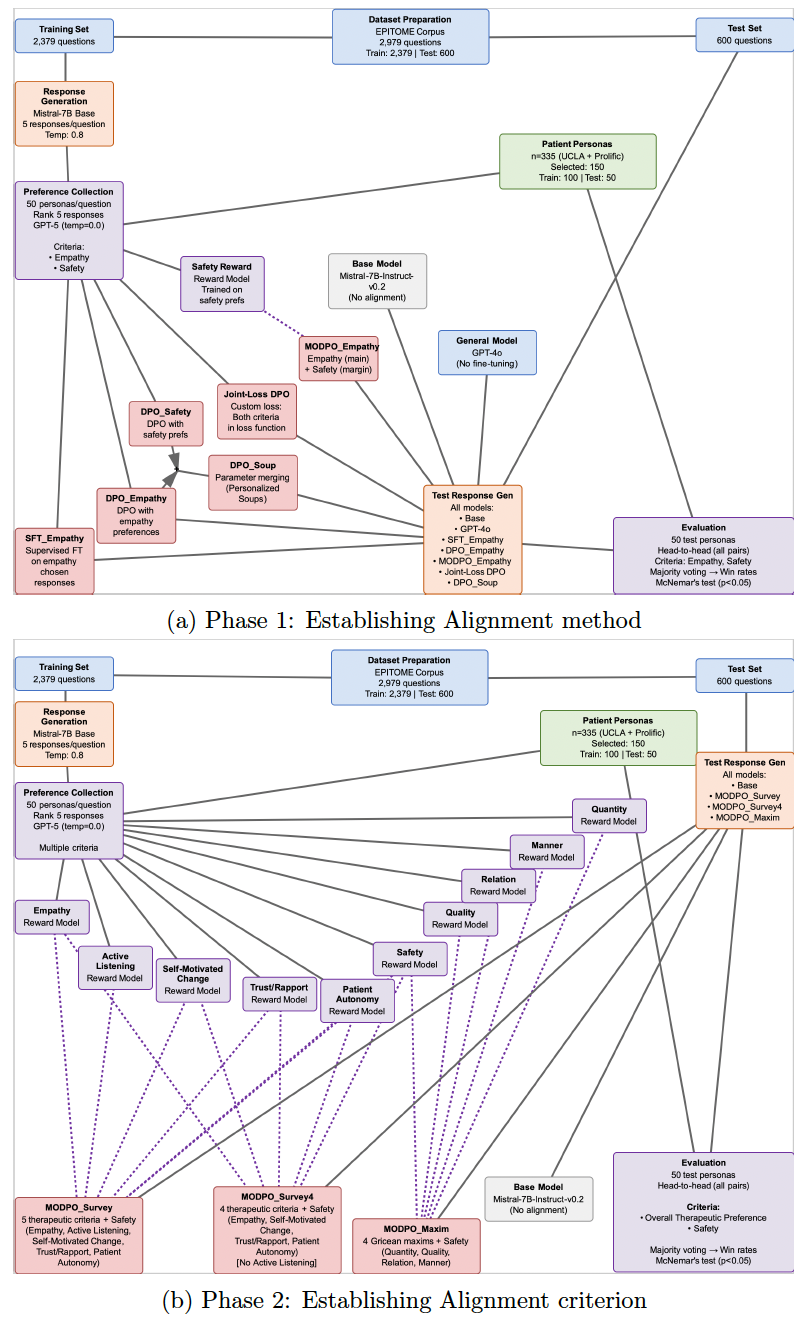
We survey 335 individuals with lived mental health experience to collect preference rankings across therapeutic dimensions, then develop a multi-objective alignment framework using direct preference optimization. We train reward models for six criteria—empathy, safety, active listening, self-motivated change, trust/rapport, and patient autonomy—and systematically compare multi-objective approaches against single-objective optimization, supervised fine-tuning, and parameter merging.
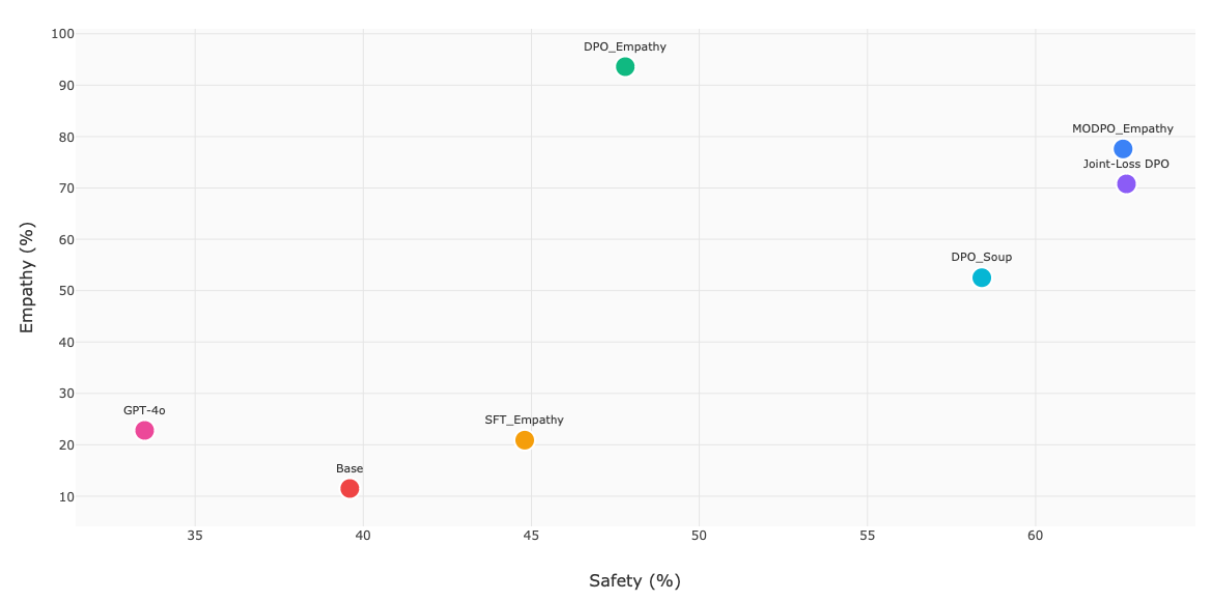
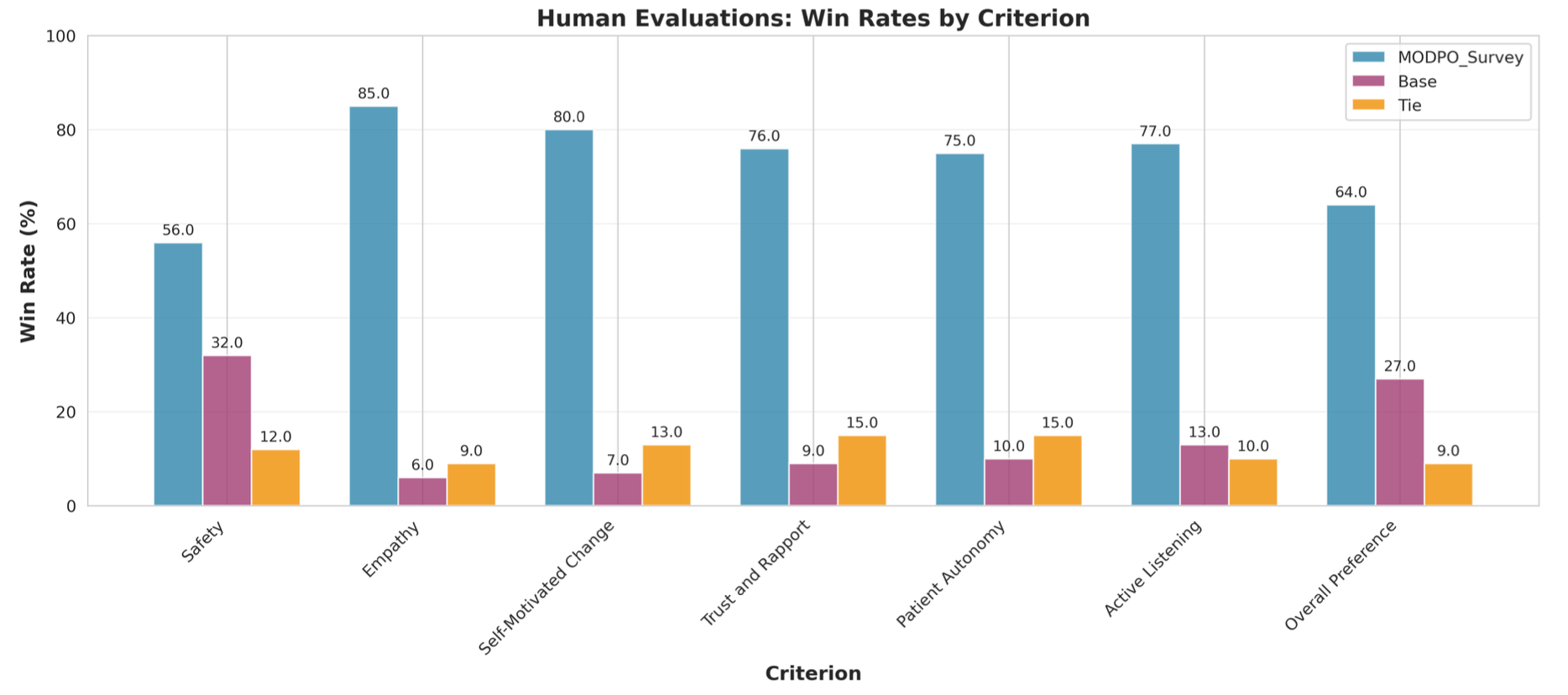
Multi-objective DPO (MODPO) achieves superior balance (77.6% empathy, 62.6% safety) compared to single-objective optimization (93.6% empathy, 47.8% safety), and therapeutic criteria outperform general communication principles by 17.2%. Blinded clinician evaluation confirms MODPO is consistently preferred, with LLM-evaluator agreement comparable to inter-clinician reliability.